Beyond Precision and Recall: The 3 Pillars of Building a Cognitive Business
The cold reality of hard-coded rules surrounding us doesn’t quite capture the nuances of our experience. Rigid rules run our social systems and organizations, giving us the illusion of security. At times ideal candidates don’t get hired because they lack a certain certificate of privilege. Other times people get locked out of their bank accounts when logging in from a dodgy cyber cafe in Thailand.
It is convenient to dismiss such annoyances, but in the personalization era it’s handling these edge cases that becomes a primary competitive advantage. Given their rich contextual awareness, cognitive systems will increasingly replace rule-based systems. Cognitive systems don’t only provide a basis for truly personalized products and services, but will (assist experts) make more nuanced decisions in a multitude of high-stake business cases, such as hiring your next CEO or preventing cyber attacks.
This blog post outlines the roadblocks in building cognitive businesses, and demonstrates why understanding context is the key to implementing expert systems with cognitive decision-making. You’ll see why better-performing machine learning algorithms are not the (primary) remedy, and how tuning the business context in which algorithms operate is of key importance. But first things first.
From rigid rules to cognitive computing
Cognitive computing mimics the functioning of the human brain to understand situations and to make decisions. It replaces rigid rules by being adaptive, interactive and context aware in nature. Theory provides a quick and easy recipe for building a cognitive system that somewhat understands a knowledge domain:
- Blend expert knowledge (rules, research report or web text) with machine-generated data (user logs or usage history)
- Add a hint of machine learning to tune the decision making process in the context of new information pouring in
Precision is not the answer
Based on the above, it might be tempting to build fancy models and to obsess over prediction accuracy. While sophisticated models with a narrow analytic objective have been widely used by human experts, they only get us so far. A model is only as valuable as the decisions it enables.
Organizations are multiplicative systems, and as most predictive models operate within the realm of KPIs, human judgment, and questionable data quality, their utility is bound to the constraints of their realities. Implementing better machine learning models is analogous to improving one’s sheer logical reasoning capacity; it’s extremely important but essentially useless in everyday situations without an understanding of the surrounding social or business context.
Cognitive computing combines the contextual awareness and adaptability of humans with the computational capacity of machines. Understanding and tweaking the context in which models operate is the real challenge and an absolute priority. With deep awareness of the business context is it only appropriate to focus on implementing more sophisticated models. To understand what constitutes a decision context, let’s quickly review the components of a cognitive system.
The cognitive architecture
It’s easy to spot the parallels between artificial cognitive systems and the human brain. Information pours in through senses, gets processed and interpreted based on personality and learnt biases, to then trigger (un)conscious thoughts and actions. Cognitive systems work similarly:
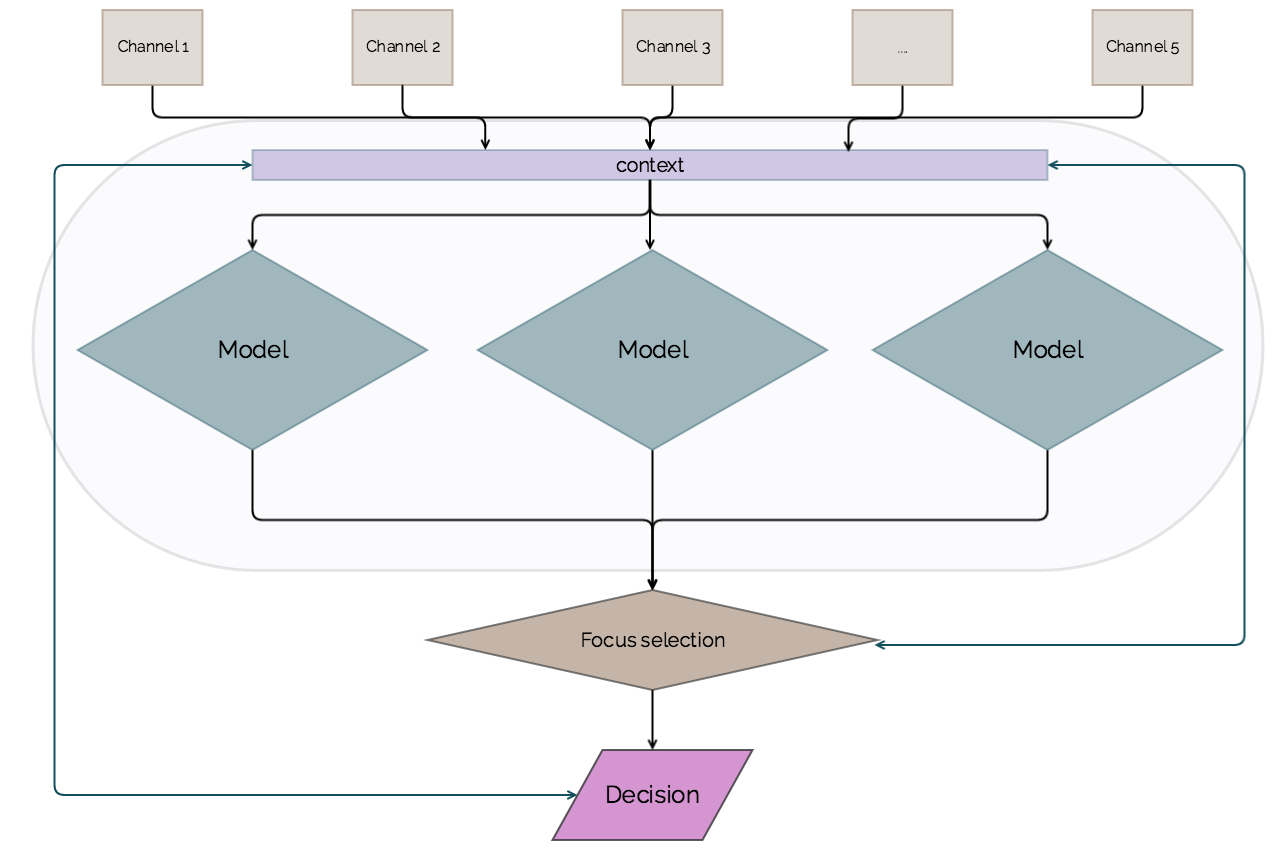
Decision = [(input → model) nested in context] modulated by focus
Data streams
On the top you can see channels for the incoming data streams, like events on a website, network traffic, or a flow of tweets. The diversity and granularity of the incoming data can be arbitrarily chosen. In hopes of utilizing contextual information one day, organizations have to balance their data hoarding tendencies with the costs of data storage. The takeaway is that at any given time, the aggregate of all incoming data streams forms the decision context.
The analytics layer
The middle layer of the above diagram encompasses all historical data, priors, trained models and learnt biases. Even expert knowledge, some claim. Each of the processing entities (or models) consume some synesthetic combination of incoming data streams. After doing their magic and providing a more or less interesting output, focus selection comes into play to pick the most relevant combination of results, worthy of attention. Notice that focus is highly sensitive to the decision context.
While building these models makes for arguably the most exciting and cutting-edge research problems (attracting a ton of attention in industry and in academia), this article focuses on how this layer is influenced by a business context.
Selecting the focus
Choosing a focus is a subjective task, you might rightfully wonder. It’s still quite fuzzy how our brains decide what we end up consciously perceiving, but in the case of an artificial cognitive system this is determined by the business objective and the decision context defined by the input. This might seem abstract, but I’ll walk you through how the cognitive architecture — context and focus in particular — comes into play in a business setting.
Building the context for a cognitive business
The three main pillars of replacing rule-based systems are an improved decision context, adaptive models and a business metrics-driven focus. They require non-trivial execution and engineering practices, and figuring each one out is a competitive advantage in and of itself.
Step 1: Improve the decision context
Building a system that resembles thinking requires gathering lots of peripheral information, usually in the form of noisy, unstructured and seemingly unimportant data. While decisions require identifying common patterns, it’s equally important to understand the yet unknown but acceptable deviations from those patterns or norms. When relying on rules of thumb in yet unseen cases, intelligence becomes synonymous with context awareness.
Increasing the diversity of data sources to validate and to give context to each other pays off down the road, and is what makes the real difference in the flexibility and precision of cognitive systems. Having contextual information about the user — such as typing and navigation patterns, network and browser characteristics, device fingerprints or purchasing habits —facilitates an in-depth understanding of the individual while making it virtually impossible for anyone else to mimic their unique behavior characteristics. Bringing such detailed user information together in a usable form is a non-trivial engineering problem. Here we elaborate on the practices to effectively aggregate and utilize contextual data, and share what we learned while transforming ThreatMark into a cognitive business.
Step 2: Implement adaptive models
Effectively utilizing contextual data has an important role in training and tuning models to fit individual users or changing business objectives. Once a general model is built, a cognitive system can start tweaking it to fit edge cases or individual users. For example, a model of an individual user should continuously change in light of the new behavioral patterns the user exhibits, or in light of the new types of information that become available over time.
In addition, changing business objectives should also influence and tune the models within a cognitive system. In the case of online fraud detection for example, if the objective is to be extremely certain that only fraudulent users get locked out, you care about precision. If the objective is never to miss a fraudulent transaction, you care about recall. Generally, every model can be tuned based on the desired tradeoff between being precise and finding all of the instances of a certain type. For instance, the fraud prevention model should be tuned such that the profit from blocking transactions (profit from being correct — cost of mistakes) is maximized. However, as business objectives change, so does the value of being overly precise or the cost of being wrong, requiring algorithms to dynamically adapt to these changes.
Step 3: Have a metrics-driven focus
While it is important to tune the algorithms based on business objectives, beyond tuning, managers and executives have to understand the actual range of benefits and the limitations of a cognitive strategy. Tempted to go data-driven, some naively fall for the vision of ambitious data scientists, without a careful assessment of whether the benefits of automation outweigh the costs and implementation risks. Sometimes it makes more sense to employ a handful of human experts. The key is to always precisely quantify the effects of implementing cognitive systems in terms of business metrics and KPIs.
Furthermore, the enterprise adoption of AI systems can pose challenges. While it is possible to train cognitive systems to be aware of their own limitations and to apply models based on business objectives or the quality or quantity of the available data, it’s beyond these systems how employees will interact with them. Some will fall in in love with the sophisticated models and rely on them unconditionally, while others will stubbornly overwrite the unbiased decisions of a system, claiming the superiority of their human intuition and experience. The bottom line is, no matter how much data there is or how adaptive models are, awareness of the limitations of expert systems goes a long way!
Related Articles
-
 November 21, 2025
Germany’s New Fraud Reality: Inside a Rapidly Evolving Scam Landscape
Germany is facing one of Europe’s fastest-rising scam and cybercrime waves, from deepfake investment ads to large-scale fraud...
November 21, 2025
Germany’s New Fraud Reality: Inside a Rapidly Evolving Scam Landscape
Germany is facing one of Europe’s fastest-rising scam and cybercrime waves, from deepfake investment ads to large-scale fraud...
-
 October 8, 2024
Spain’s Cybercrime Problem: What Banks Should Learn from the Santander Data Breach
Spain recently made headlines when one of its largest banks, Santander, fell victim to a hacker attack. This...
October 8, 2024
Spain’s Cybercrime Problem: What Banks Should Learn from the Santander Data Breach
Spain recently made headlines when one of its largest banks, Santander, fell victim to a hacker attack. This...
-
 June 14, 2024
Overcoming Latin America’s Digital Fraud Challenges
Latin America is among the regions most troubled by payment fraud worldwide.
This success of fraudsters stems from multiple...
June 14, 2024
Overcoming Latin America’s Digital Fraud Challenges
Latin America is among the regions most troubled by payment fraud worldwide.
This success of fraudsters stems from multiple...